AI Multi-Agent Chat Platform for Websites (No-Code SaaS)
Our Solution
We designed and built a no-code multitenant SaaS platform for orchestrating AI chatbots that embed directly into any website. The system operates as an intelligent multi-agent architecture rather than a single chatbot:
Orchestration Layer: An AI router classifies incoming user messages and dispatches them to the most relevant sub-agent. When routing is ambiguous, the orchestrator asks targeted clarification questions — and learns from human-provided routing examples, improving its accuracy over time without retraining.
Sub-Agent Layer: Each specialized agent is bound to a category of documents in the knowledge base. Before answering, the agent systematically collects structured data from the user — field by field — handles counter-questions without losing context, and only then formulates a search query against its RAG pipeline. If the answer is found, it responds; if not, it can escalate to a human operator with the collected data sent via email.
Integration Layer: A lightweight Preact widget distributed as a single IIFE JavaScript file embeds on any website through Shadow DOM isolation. Telegram is supported as a second channel through a unified DeliveryChannel protocol — the same business logic serves both web and messenger users without duplication.
Every conversation follows a strict FSM: CLASSIFICATION → COLLECTION → ANSWERING → HANDOFF. Invalid transitions fall back to CLASSIFICATION, ensuring the system never gets stuck in an inconsistent state.
A demo version of the service is available at: https://easy-chat.live/
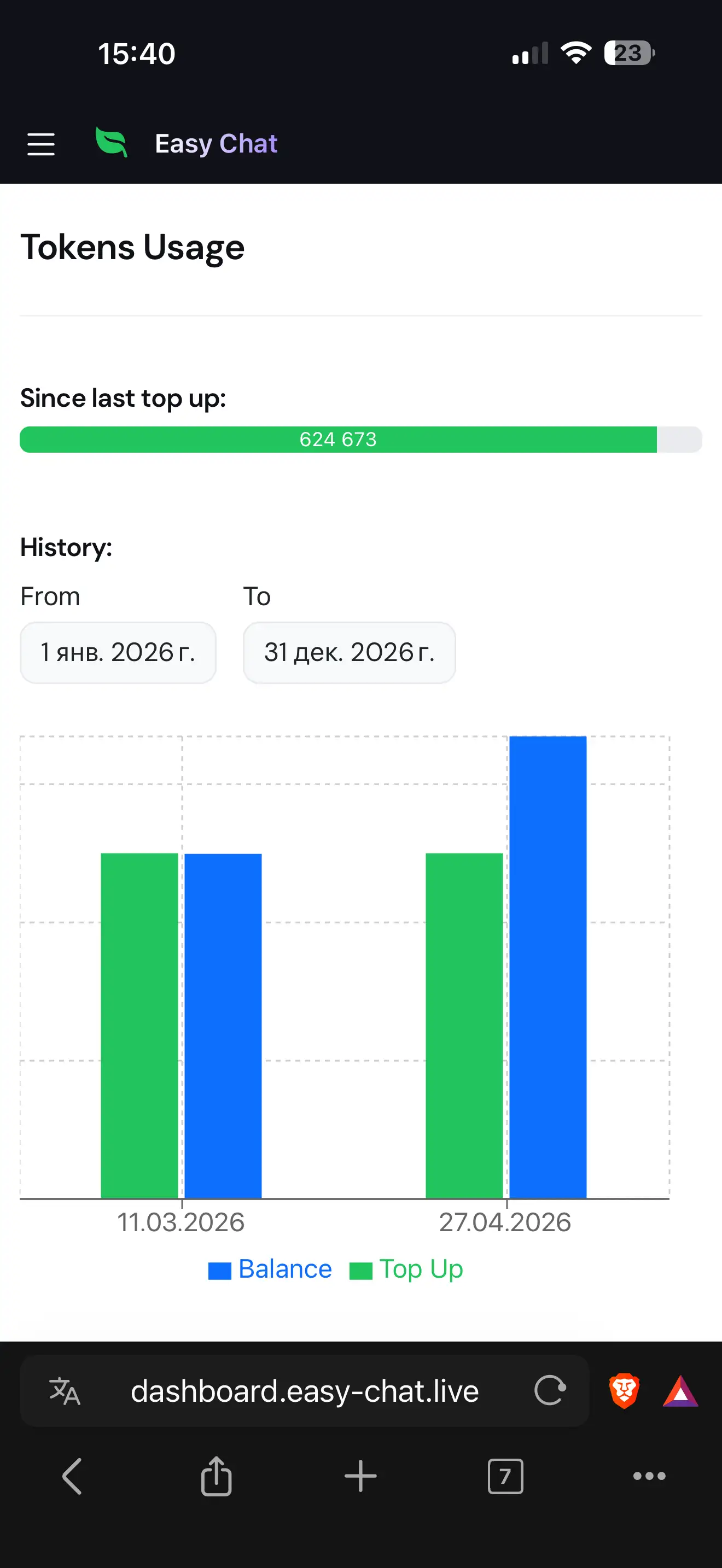
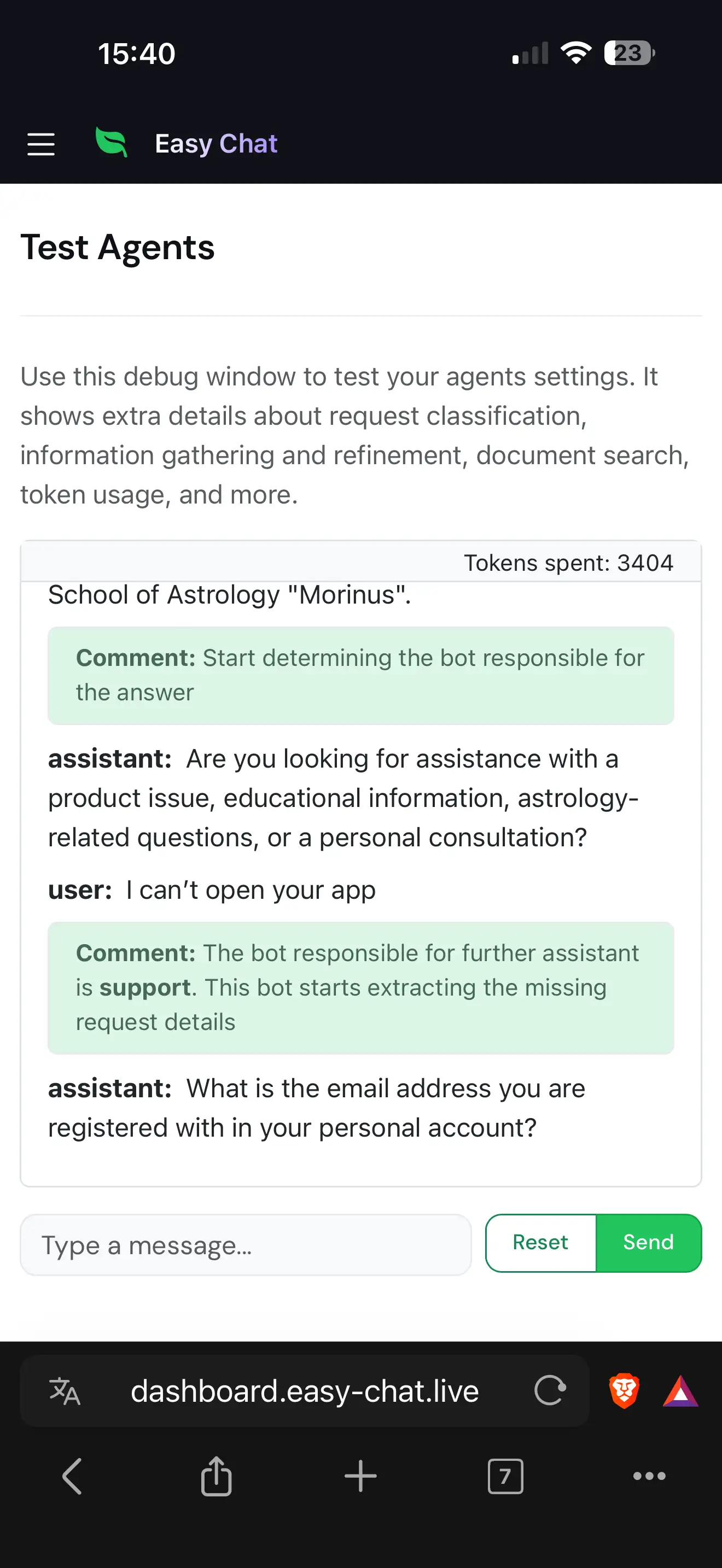

Results Achieved
- Human-in-the-Loop Routing Improvement: Unlike static LLM-based classifiers, the orchestrator improves continuously — managers add routing examples for misclassified queries directly from the dashboard, teaching the system to handle edge cases without any model retraining or engineering effort.
- Structured Data Collection with Conversational UX: The data collection phase handles real human behavior: counter-questions are preserved and answered later, clarification requests are explained from field descriptions, and irrelevant responses trigger re-asks (up to 3 attempts before skipping). No rigid form-filling — just natural conversation.
- Resilient by Design: Four independent circuit breakers protect external LLM and embedding APIs from cascading failures. Celery tasks use
pg_advisory_xact_lockfor sequential per-chat ordering, preventing race conditions on shared state. WebSocket sessions survive reconnections with full state recovery from Redis/SQL. - True Multi-Channel Architecture: The
DeliveryChannelprotocol decouples business logic from transport — adding a new channel (WhatsApp, VK) requires only a delivery manager implementation, not duplication of the FSM, RAG pipeline, or data collection logic. Telegram integration was delivered as the first proof of this architecture. - Zero-Friction Deployment: The widget is a single IIFE file served with CORS and 1-year immutable cache — one
<script>tag on any website activates the full chat experience in Shadow DOM isolation. Organizations onboard through a 9-step wizard and get 500K free tokens.
Technology Stack
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The project uses a specialized stack designed for real-time AI-driven conversation processing at scale.
- The Python/FastAPI backend serves as the core framework, handling REST API, WebSocket chat sessions, and background task orchestration via Celery. FastAPI was chosen for native async support and automatic OpenAPI documentation, which is critical for the real-time WebSocket-driven chat architecture.
- Haystack AI powers the RAG pipeline: document chunking, Cohere multilingual embeddings, Pgvector similarity search (HNSW, cosine), and
ContextExtractorfor neighboring-chunk enrichment — all orchestrated through 14 specialized pipelines with temperature-tuned prompts for classification, data extraction, answer formulation, and handoff decisions. - PostgreSQL with pgvector serves dual duty: relational storage for the multitenant data model (organizations, users, agents, documents, chat logs) and vector similarity search for RAG. Redis handles session state, distributed locks, Celery brokering, and inbox-based message processing with atomic Lua scripts.
- The React + TypeScript dashboard manages complex state across 7 global reducers (
useReducerexclusively, no external state library) with a layer-based navigation system. The Preact widget compiles to a single IIFE bundle with Shadow DOM isolation, while Astro generates the static marketing site with JSON-LD structured data for SEO. - The entire application is containerized with Docker Compose, deployed through a GitHub Actions CI/CD pipeline on a self-hosted runner. Nginx handles TLS termination, reverse proxying, and static asset serving. Circuit breakers, connection limits, and rate limiting provide defense in depth.